Evolve Interview Project¶
Zoë Farmer¶

Press the space-bar to proceed to the next slide. See here for a brief tutorial
Who am I?¶
- My name is Zoë Farmer
- Recent CU graduate with a BS in Applied Math and a CS Minor
- Co-coordinator of the Boulder Python Meetup
- Big fan of open source software
- http://www.dataleek.io
- @thedataleek
- git(hub|lab).com/thedataleek
General Tooling Overview¶
- Everything is in Python3.6
- I use
jupyter,pandas,numpy,matplotlib,scikit-learn,nltk, andscipy. - Some code has been skipped for brevity. See this link for full code.
- Development performed with Jupyter Notebook, this notebook is available at the above link.
- Presentation powered by Reveal.js





The Data¶
What is it?¶
A year of data about Boston scraped from AirBnB that contains 2 datasets
- listing details
- calendar information
(1) Listings - details about locations¶
Our first dataset is a large number of listings and associated descriptions.
listing_data = pd.read_csv('./ListingsAirbnbScrapeExam.csv')
len(listing_data)
3585
', '.join(listing_data.columns)
'id, name, summary, space, description, experiences_offered, neighborhood_overview, notes, transit, access, interaction, house_rules, host_name, host_since, host_location, host_about, host_response_time, host_response_rate, host_acceptance_rate, host_is_superhost, host_neighbourhood, host_listings_count, host_total_listings_count, host_verifications, host_has_profile_pic, host_identity_verified, street, neighbourhood_cleansed, city, state, zipcode, market, smart_location, country_code, country, latitude, longitude, is_location_exact, property_type, room_type, accommodates, bathrooms, bedrooms, beds, bed_type, amenities, square_feet, price, weekly_price, monthly_price, security_deposit, cleaning_fee, guests_included, extra_people, minimum_nights, maximum_nights, calendar_updated, has_availability, availability_30, availability_60, availability_90, availability_365, calendar_last_scraped, number_of_reviews, first_review, last_review, review_scores_rating, review_scores_accuracy, review_scores_cleanliness, review_scores_checkin, review_scores_communication, review_scores_location, review_scores_value, requires_license, license, jurisdiction_names, instant_bookable, cancellation_policy, require_guest_profile_picture, require_guest_phone_verification, calculated_host_listings_count, reviews_per_month'
(2) Calendar Data - location occupancy by date¶
Our second dataset is a set of listings by date, occupancy, and price.
- We want to parse these fields
- datestrings to be formatted as python
datetimeobjects - price field to be floats
- datestrings to be formatted as python
calendar_data = pd.read_csv(
'./CalendarAirbnbScrapeExam.csv',
converters={
'available': lambda x: True if x == 'f' else False,
'price': price_converter
}
)
calendar_data['filled'] = ~calendar_data['available']
calendar_data['date'] = pd.to_datetime(calendar_data['date'],
infer_datetime_format=True)
calendar_data.head(1)
| listing_id | date | available | price | filled | |
|---|---|---|---|---|---|
| 0 | 12147973 | 2017-09-05 | True | NaN | False |
Dataset Merge¶
We want to combine datasets
- Let's calculate the number of nights occupied per listing and add to the listing data.
- Average/standard deviation price per night
But let's first make sure the datasets overlap.
listing_keys = set(listing_data.id)
calendar_keys = set(calendar_data.listing_id)
difference = listing_keys.difference(calendar_keys)
print(f'# Listing Keys: {len(listing_keys)}')
print(f'# Calendar Keys: {len(calendar_keys)}')
print(f'# Difference: {len(difference)}')
# Listing Keys: 3585 # Calendar Keys: 2872 # Difference: 713
They don't, in fact we're missing information on about 700 listings.
For our num_filled column let's establish the assumption that a NaN value stands for "unknown".
Groupby¶
We can simply sum() our available and filled boolean fields. This will give us a total number of nights occupied (or available).
Note, in the final aggregated sum these two fields sum to 365.
fill_dates.head()
| available | filled | price | listing_id | ||
|---|---|---|---|---|---|
| sum | sum | mean | std | ||
| listing_id | |||||
| 5506 | 21.0 | 344.0 | 147.267442 | 17.043196 | 5506 |
| 6695 | 41.0 | 324.0 | 197.407407 | 17.553300 | 6695 |
| 6976 | 46.0 | 319.0 | 65.000000 | 0.000000 | 6976 |
| 8792 | 117.0 | 248.0 | 154.000000 | 0.000000 | 8792 |
| 9273 | 1.0 | 364.0 | 225.000000 | 0.000000 | 9273 |
Left Join¶
Now we merge with our original dataset using a left join.
combined_data = listing_data.merge(
fill_dates,
how='left',
left_on='id',
right_on='listing_id'
)
combined_data.rename(
columns={
('available', 'sum'): 'available',
('filled', 'sum'): 'filled',
('price', 'mean'): 'avg_price',
('price', 'std'): 'std_price'
},
inplace=True
)
/home/zoe/.local/lib/python3.6/site-packages/pandas/core/reshape/merge.py:551: UserWarning: merging between different levels can give an unintended result (1 levels on the left, 2 on the right) warnings.warn(msg, UserWarning)
combined_data[['id', 'name', 'available', 'avg_price', 'std_price']].head(10)
| id | name | available | avg_price | std_price | |
|---|---|---|---|---|---|
| 0 | 12147973 | Sunny Bungalow in the City | 365.0 | NaN | NaN |
| 1 | 3075044 | Charming room in pet friendly apt | 6.0 | 67.813370 | 4.502791 |
| 2 | 6976 | Mexican Folk Art Haven in Boston | 46.0 | 65.000000 | 0.000000 |
| 3 | 1436513 | Spacious Sunny Bedroom Suite in Historic Home | 267.0 | 75.000000 | 0.000000 |
| 4 | 7651065 | Come Home to Boston | 31.0 | 79.000000 | 0.000000 |
| 5 | 12386020 | Private Bedroom + Great Coffee | 307.0 | 75.000000 | 0.000000 |
| 6 | 5706985 | New Lrg Studio apt 15 min to Boston | 21.0 | 111.755814 | 18.403439 |
| 7 | 2843445 | "Tranquility" on "Top of the Hill" | 0.0 | 75.000000 | 0.000000 |
| 8 | 753446 | 6 miles away from downtown Boston! | 18.0 | 59.363112 | 3.629618 |
| 9 | 849408 | Perfect & Practical Boston Rental | 258.0 | 252.925234 | 31.012992 |
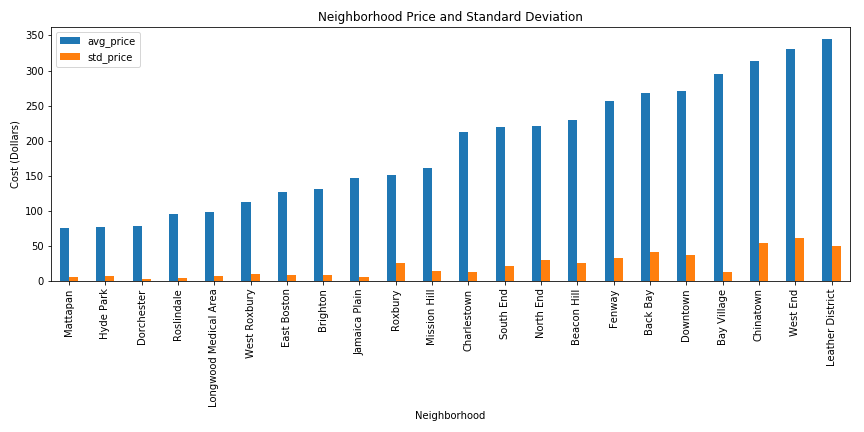
Neighborhood Statistics¶
Now that we've added those columns to the listing data, we can start to get neighborhood-specific statistics.
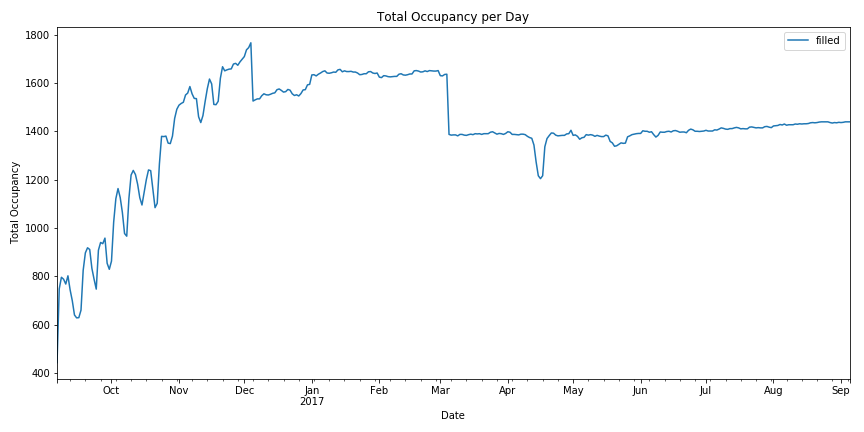
Seasonal Trends¶
We have a year of data, let's examine how seasons effect occupancy.
We can take a naive approach and simply groupby each date and plot the number of dates filled.
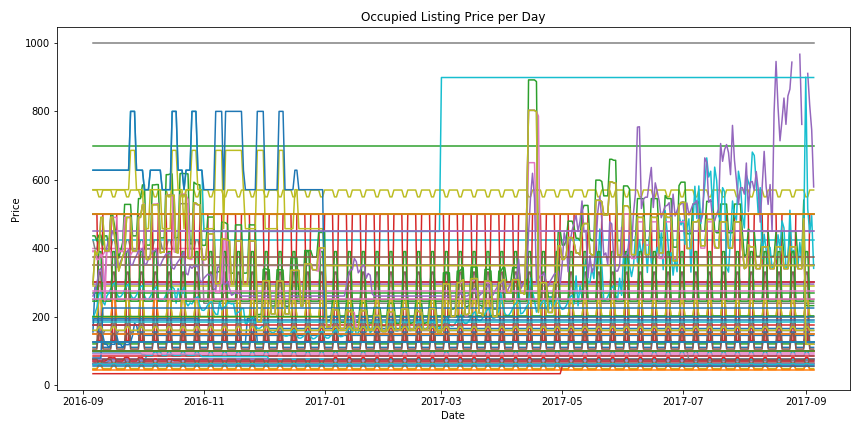
Let's do better¶
This chart has some irregularities and is a little unclear about the type of trends we're looking for.
Let's look at only the listings that are filled each day of the year, and look at their prices as the year goes by.
We'll refer to these as "indicator listings".
print(f'Original Datasize: {len(calendar_data.listing_id.unique())}.')
print(f'Pruned Datasize: {len(top_listings)}')
Original Datasize: 2872. Pruned Datasize: 81
This shrinks our dataset by a lot, but that's ok.
We're looking for indicator listings, not the entire dataset.
Plotting our Busy Listings¶
Reducing Noise¶
This chart has too much noise and the trends are even less clear.
- Remove all listings with low standard deviation
- $10 < \sigma < 200$
- Also cut out all listings that only have a few unique values
- $\left\lvert \left\{ X \right\}\right\rvert > 10$
- Periodicity is the enemy of seasonal trends
sensitive_listings
| stddev | num_unique | |
|---|---|---|
| listing_id | ||
| 5455004 | 139.340961 | 108 |
| 6119918 | 128.657169 | 216 |
| 8827268 | 155.416406 | 189 |
| 14421304 | 128.396181 | 96 |
| 14421403 | 127.944730 | 105 |
| 14421692 | 127.944730 | 105 |
Plotting our Indicator Listings¶
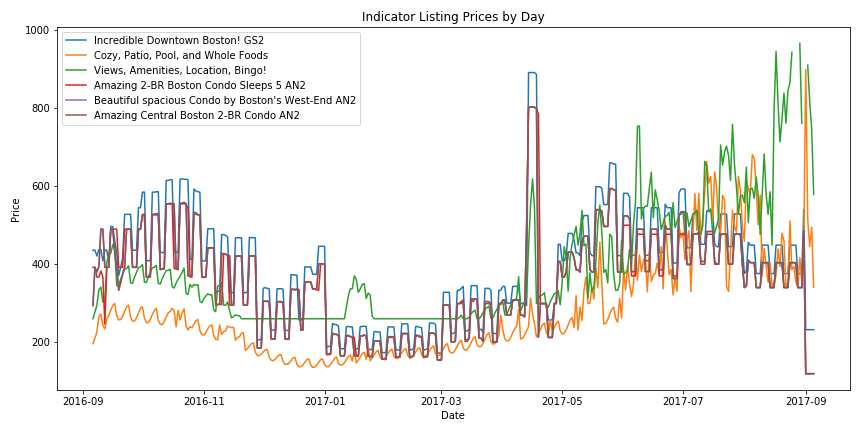
Combining Naive Occupancy and Indicator Listings¶
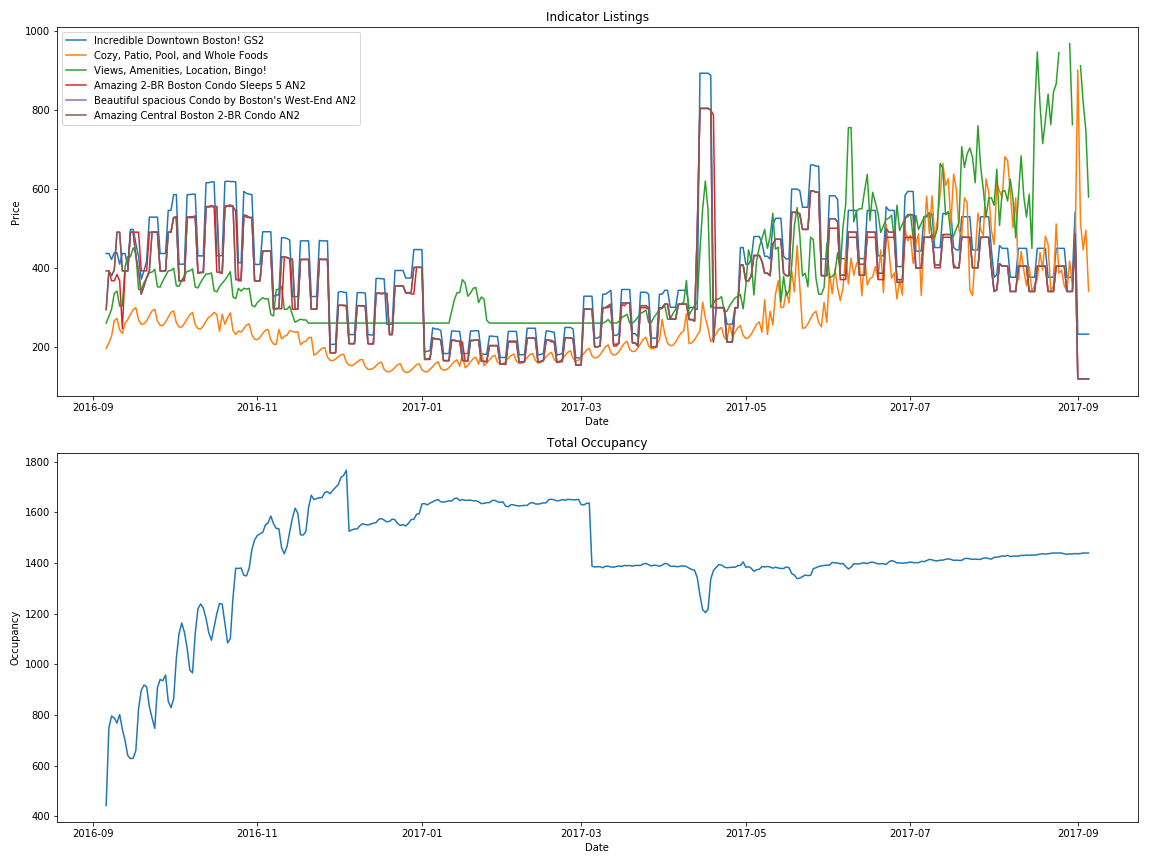
What does this tell us?¶
- Winter was the busy season for 2016-2017
- Most likely because of family/holidays
- Also the cheapest
- Summers are expensive
- Memorial Day Weekend is expensive (the spike in the middle)
- The start of MIT school year is expensive (spike at the right side)
- Visit Boston between New Years and March for the cheapest rates.
- Weekends are more expensive than weekdays, but this doesn't influence occupancy.
- Our naive approach looks weird in Fall 2016 due to AirBnB's increased activity in the area
- According to a ton of news sources, this was an year of protest for AirBnB. This is probably skewing the data
These are good preliminary results, but for more accurate results we'd want several years to reduce influence of increased activity, year specific events, legal actions, etc.
Neighborhood Specific Seasonal Trends¶
Let's dig into any seasonal trends we can find on a neighboorhood basis.
full_combined_data = listing_data.merge(
calendar_data,
how='inner',
left_on='id',
right_on='listing_id'
)
Let's plot each neighborhood by their average price and fill-rate per day.
neighborhood_data = full_combined_data\
.groupby(['neighbourhood_cleansed', 'date'])\
.agg({'filled': 'sum', 'price_y': 'mean'})
neighborhood_data = neighborhood_data.unstack(level=0)
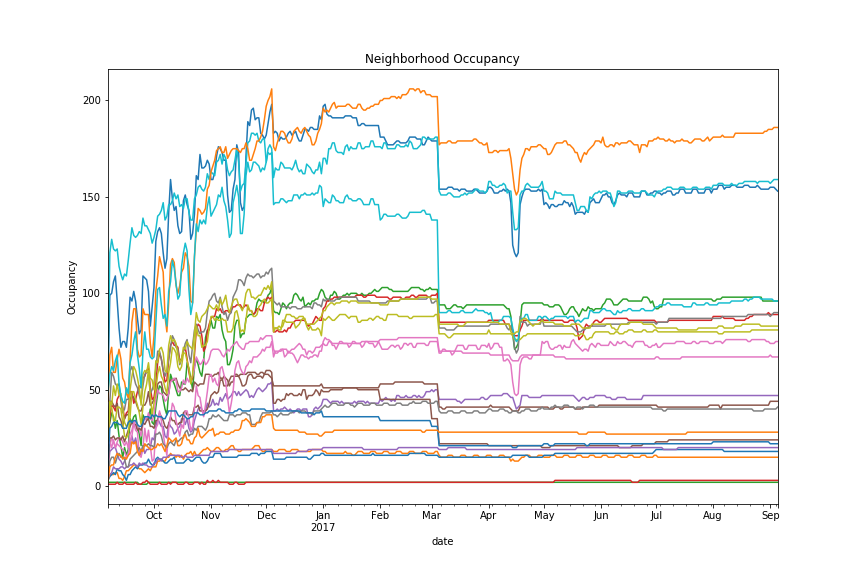
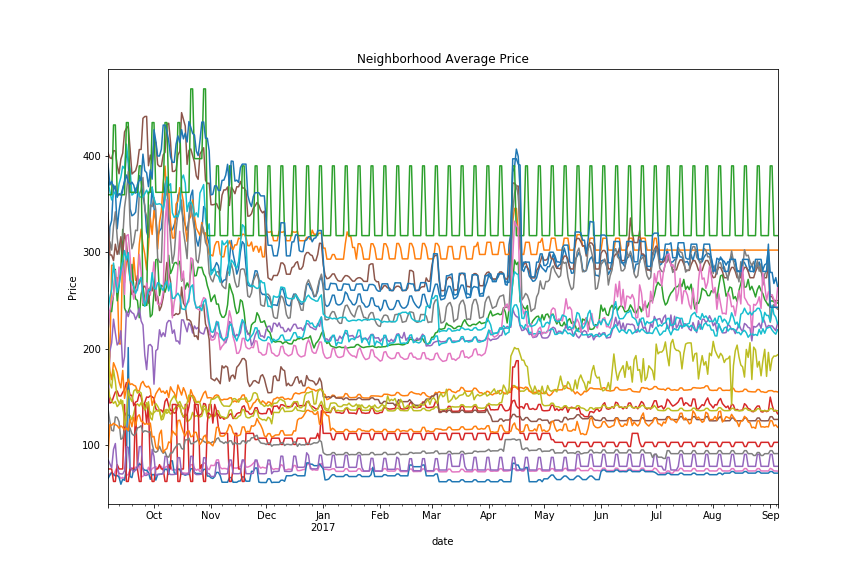
What does this tell us?¶
- As with before, Memorial Day Weekend stands out as a spike in pricing and a drop in occupancy
- Weekends are more expensive
- December and March 1st have a huge drop in occupancy and pricing
- Not every seasonal trend affects every neighborhood! Some are immune (or do the opposite) of the average trend.
As with before, we'd ideally want more data to make more accurate observations.
Examining Neighborhoods¶
Let's also see if we can pull out neighbor features.
Some listings don't have neighborhood descriptions, so let's skip those.
neighborhood_labels
array(['Roslindale', 'Jamaica Plain', 'Mission Hill',
'Longwood Medical Area', 'Bay Village', 'Leather District',
'Chinatown', 'North End', 'Roxbury', 'South End', 'Back Bay',
'East Boston', 'Charlestown', 'West End', 'Beacon Hill', 'Downtown',
'Fenway', 'Brighton', 'West Roxbury', 'Hyde Park', 'Mattapan',
'Dorchester', 'South Boston Waterfront', 'South Boston', 'Allston'], dtype=object)
How many listings per neighborhood?¶
valid_desc_data.groupby('neighbourhood_cleansed').agg('size').sort_values()
neighbourhood_cleansed Leather District 5 Longwood Medical Area 6 Mattapan 14 Hyde Park 15 Bay Village 19 West Roxbury 24 West End 32 South Boston Waterfront 41 Roslindale 42 Chinatown 46 Charlestown 53 Mission Hill 58 East Boston 87 North End 88 Roxbury 92 Brighton 105 Downtown 108 South Boston 114 Beacon Hill 131 Dorchester 144 Allston 146 Fenway 148 Back Bay 181 South End 225 Jamaica Plain 246 dtype: int64
Where are these neighborhoods?¶

Top 5 Neighborhoods¶
Let's only take the top 5 neighborhoods with the most listings.
top5_neighborhoods
['Allston', 'Fenway', 'Back Bay', 'South End', 'Jamaica Plain']
Now let's make a word cloud for each neighborhood based on the most common words in their descriptions.
Allston¶

Fenway¶
Back Bay¶

South End¶

Jamaica Plain¶

Feature Extraction¶
Wordclouds are pretty, but also fairly crude. Let's take a deeper dive into these top 5 neighborhoods.
top5_fulltext = top5_listings[['neighbourhood_cleansed',
'neighborhood_overview']]
top5_fulltext.head(3)
| neighbourhood_cleansed | neighborhood_overview | |
|---|---|---|
| 59 | Jamaica Plain | The neighborhood is complete with all shops, r... |
| 60 | Jamaica Plain | Downtown Jamaica Plain is a delight with plent... |
| 61 | Jamaica Plain | the neighborhood is exactly that ... a neighbo... |
Term Frequency - Inverse Document Frequency¶
From Wikipedia,
tf–idf, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpu
In essence, the product of "how common a word is in the corpus" and "inverse of how frequently the term appears in the document set".
Using this concept we can construct a document matrix, where each row represents a document in the corpus, and each column represents a word that appeared.
The big difference between this approach and our wordcloud approach from earlier which just relies on raw frequency is that this takes into account the overall frequency of the word in the entire document set.
Scikit-Learn¶
sklearn provides several vectorizers, including a tf-idf vectorizer.
We give it a tokenizing regular expression in order to prune less relevant tokens (a token is just a unit of semantic meaning, in this case we only want words longer than 3 characters).
We're going to feed this all of the listing descriptions from our top 5 neighborhoods and aggregate later.
fit = vect.fit(top5_cleantext)
X = vect.fit_transform(top5_cleantext)
The shape of this document matrix, $946 \times 1599$, indicates there are $946$ documents, and $1599$ tokens.
This matrix is incredibly sparse however (only about 0.5% full), since not every token appears in every document.
X.shape
(946, 1599)
X.astype(bool).sum() / (946 * 3019)
0.0049293165834142748
Using tf-idf¶
Now that we have our document matrix, let's use it to figure out the most important words per document.
print(summary)
South End: distanc, yourself, brownston, locat, young, across, years, wrought, would, worlds, world, wonder, discov, within, dinner, beauti Fenway: dynam, young, museum, attract, years, would, worth, worri, wonder, anyth, women, without, within, multicultur, moist, modern Back Bay: hospit, years, convention, wrong, convent, worth, appreci, homes, block, histori, wonder, histor, within, conveni, almost, window Jamaica Plain: zagat, yummi, lucki, youth, yourself, younger, distanc, young, along, longer, locations, burger, locat, would, worth, worst Allston: minut, youth, decid, younger, blocks, culture, young, block, anywher, activ, cultur, biking, between, midst, world, midnight
What does this tell us?¶
- Stemming (converting words to their "base" form) is tricky, and innacurate
- Tf-Idf emphasizes words that appear in fewer documents
- This gives us a better summary instead of just seeing "Boston" for every neighborhood
- The advantage this provides over just word frequencies is that we see the important things that aren't mentioned frequently.
- South End:
- Located in a good spot, younger crowd, good restaurants, "deeper beauty".
- Fenway
- Younger crowd, has museums, multicultural, modern.
- Back Bay:
- Hospital access, conventions here, high value, historical districts
- Jamaica Plain:
- Lots of zagat-reviewed restaurants, good food here, younger crowd.
- Allston:
- Younger crowd, access to outdoors activities (biking, etc.), active nightlife.
Conclusions¶
Seasonal Trends¶
- Winter was the busy season for 2016-2017
- Most likely because of family/holidays
- Also the cheapest
- Summers are expensive
- Memorial Day Weekend is expensive (the spike in the middle)
- The start of MIT school year is expensive (spike at the right side)
- Visit Boston between New Years and March for the cheapest rates.
- Weekends are more expensive than weekdays, but this doesn't influence occupancy.
- Our naive approach looks weird in Fall 2016 due to AirBnB's increased activity in the area
- According to a ton of news sources, this was an year of protest for AirBnB. This is probably skewing the data
- As with before, Memorial Day Weekend stands out as a spike in pricing and a drop in occupancy
- Weekends are more expensive
- December and March 1st have a huge drop in occupancy and pricing
- Not every seasonal trend affects every neighborhood! Some are immune (or do the opposite) of the average trend.
Neighborhoods¶
The Leather District, West End, and Chinatown are the most expensive places to live.
- South End:
- Located in a good spot, younger crowd, good restaurants, "deeper beauty".
- Fenway
- Younger crowd, has museums, multicultural, modern.
- Back Bay:
- Hospital access, conventions here, high value, historical districts
- Jamaica Plain:
- Lots of zagat-reviewed restaurants, good food here, younger crowd.
- Allston:
- Younger crowd, access to outdoors activities (biking, etc.), active nightlife.