
Who am I¶
- My name is Zoë Farmer
- CU graduate with a BS in Applied Math and a CS Minor
- I'm a co-coordinator of the Boulder Python Meetup
- I'm a big fan of open source software
- http://www.dataleek.io
- @TheDataLeek, github.com/thedataleek, gitlab.com/thedataleek
- Data Visualizer at Talus Analytics
In [37]:
Image('./talus-logo.png', height=300, width=300)
Out[37]:

Concurrency is not Parallelism¶
- Google "concurrency vs parallelism" for a lot of resources
- There's a good article here: https://blog.golang.org/concurrency-is-not-parallelism
- TL;DR
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
Python can do both¶
- Lots of different ways to achieve either
- Concurrency - A good example is
async/await, this handles a lot of quick interactions that are staggered - Parallelism -
os.fork()is a classic example
Concurrency¶
- A problem immediately arises if you want to do some time consuming tasks together
- Python (when threaded) can only do one thing at a time
- It will spend a lot of time jumping around, when we really just want it to do everything
- https://uwpce-pythoncert.github.io/SystemDevelopment/threading-multiprocessing.html
In [82]:
Image('gil.png', height=800, width=800)
Out[82]:

Parallelism¶
- This is where parallelism comes in
- There's no GIL switching
- Example -
os.fork() - https://dataleek.io/index.php/2017/10/24/a-quick-guide-to-os-fork-in-python/
In [86]:
import os, signal, time
pid = os.fork()
print(pid)
if pid == 0:
# Have the child do a thing
print('child starting', end='... ')
time.sleep(10)
print('child ending')
else:
# have the parent do a thing
os.kill(pid, signal.SIGINT)
Python's Multiprocessing¶
import multiprocessing- Start up new processes without
os.fork() - Communicate with
queuesandpipes - Queues are super handy, they handle memory and locks and all those nasty things that you can read about more in The little book of Semaphores
Quick Example¶
In [23]:
def worker(q, worknum):
print(f'Worker {worknum} Starting')
for i in range(2):
print(f'Worker {worknum} {q.get()}')
print(f'Worker {worknum} Exiting')
for i in range(3):
w = mp.Process(
name='example_worker',
target=worker,
args=(q, i)
).start()
for i in range(100): q.put(f'foo {i}', block=False)
Let's jump into a practical example¶
What's the goal?¶
- Personal dev workflow:
- I need to search for keywords in large codebases
find . -exec grepis slow- Can Python do better?
TL;DR without an IDE, finding arbitrary strings in a massive amount of text in a reasonably short amount of time.
Black Arrow¶
In [13]:
!ba "Boulder Python" -d /Users/zoe/projects
Why is it this fast?¶
- Multiprocessing
- Native file access
- Python uses c bindings for basic operations like reading files
- Modern SSDs
- Waaaaay faster than HDDs
- No drive head bouncing around
Black Arrow's Architecture¶
- Each block is a process
- Each arrow is a queue (or multiple)
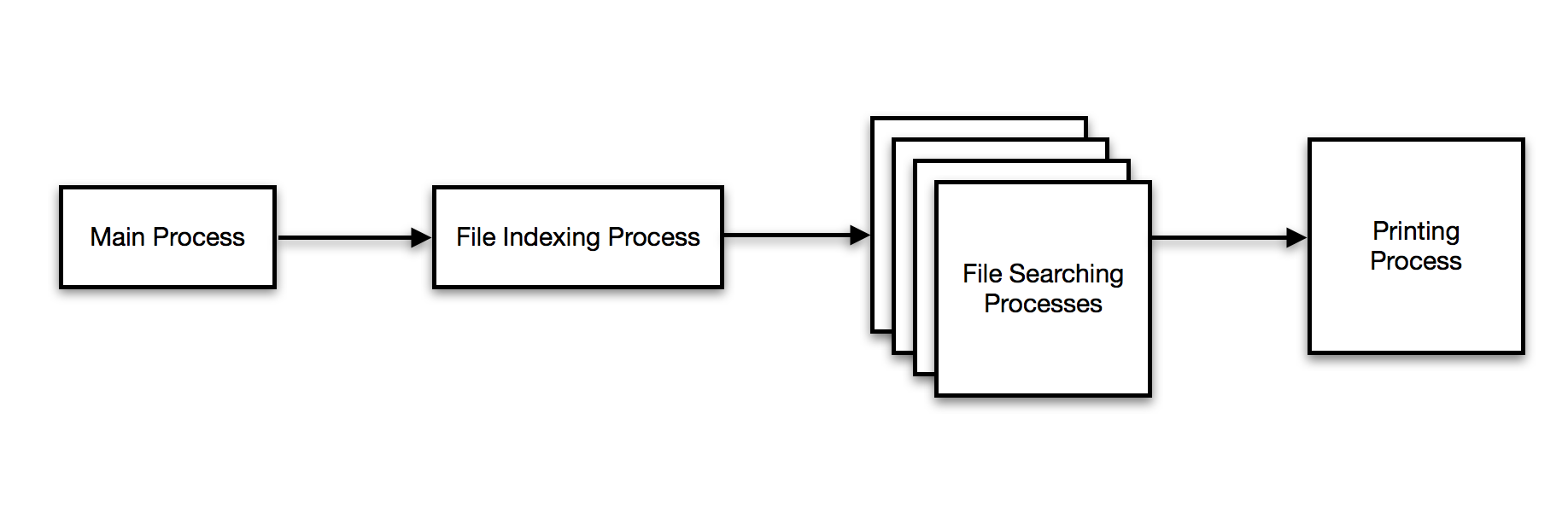
Main Process - Start all the other processes¶
- start_indexer()
- start_workers()
- start_printer()
In [24]:
def main():
args = get_args()
processes, final_queue = ba.start_search(args)
print_process = processes[-1]
try:
print_process.join() # Wait main thread until printer is done
except (KeyboardInterrupt, EOFError): # kill all on ctrl+c/d
[p.terminate() for p in processes]
File Indexing - what files exist?¶
- for every file recursively below
- add to the worker queue
In [ ]:
def index_worker(
directories: List[str], ignore_re: RETYPE, workers: int, search_queue: mp.Queue, output: mp.Queue, block=False
) -> None:
for dir in list(set(directories)): # no duplicate input
for subdir, _, files in os.walk(dir):
for question_file in files:
# we don't want to block, this process should be fastest
search_queue.put(
subdir + "/" + question_file, block=block, timeout=10
) # faster than os.path.join
for i in range(workers):
search_queue.put("EXIT") # poison pill workers
File Searching - do any files match?¶
- for every file pulled from the worker queue:
- search using grep for regex
- pass information forward to printer
In [ ]:
def file_searching_worker(
regex: RETYPE, ignore_re: RETYPE, filename_re: RETYPE, replace: Union[str, None],
search_queue: mp.Queue, output: mp.Queue,
) -> None:
# https://stackoverflow.com/questions/566746/how-to-get-console-window-width-in-python
rows, columns = os.popen("stty size", "r").read().split()
# Max width of printed line is 3/4 column count
maxwidth = int(3 * int(columns) / 4)
while True:
# we want to block this thread until we get search_queue
name = search_queue.get()
try:
with open(name, "r") as ofile:
flag = []
for line in ofile:
if regex.search(line):
found_string = line.split("\n")[0]
if len(found_string) > maxwidth:
found_string = found_string[:maxwidth] + "..."
flag.append((i, found_string))
if flag:
for value in flag:
output.put((name, value[0], value[1], regex))
except:
pass
Printing - print results¶
- print every result passed by workers
- print summary statistics
In [ ]:
def print_worker(
start_time: float, worker_count: int, output: mp.Queue,
final_queue: mp.Queue, pipemode: bool, editmode: bool,
) -> None:
while True:
statement = output.get()
if len(statement) == 4:
filename, linenum, matched, line = statement
replace = None
else:
filename, linenum, matched, line, replace = statement
final_queue.put(filename, linenum)
print(
"{}:{}\n\t{}".format(
filename,
color.fg256("#00ff00", linenum),
insert_colour(matched, line, extra_str=replace),
)
)
file_list.append((statement[1], statement[0]))
final_queue.put("EXIT")
Implementation Details¶
- Lots of queues - easy to implement, reliable, fast
- Notice those
EXITstrings we pass around? How else do we stop a child? - Why printing separately?
A programmer had a problem. He thought to himself, "I know, I'll solve it with threads!". has Now problems. two he
Questions?¶
- zoe@dataleek.io
- https://dataleek.io
- @thedataleek
Sources¶
- Async/Await - https://medium.freecodecamp.org/a-guide-to-asynchronous-programming-in-python-with-asyncio-232e2afa44f6
threading- https://docs.python.org/3/library/threading.htmlos.fork()- https://dataleek.io/index.php/2017/10/24/a-quick-guide-to-os-fork-in-python/multiprocessing- https://docs.python.org/3.4/library/multiprocessing.html?highlight=process- Little book of semaphores - http://greenteapress.com/wp/semaphores/
- Black arrow - https://github.com/thedataleek/black-arrow