Attention as a Soft Lookup Table
A minimal model built from scratch uses attention to learn color-to-noun mappings, showing how scaled dot-product attention implements a differentiable soft lookup table — and what the model learns geometrically after training.
import random
import marimo as mo
import torch
import torch.nn as nn
import numpy as np
import polars
import matplotlib.pyplot as plt
Attention as a Soft Lookup Table
Attention is the mechanism behind every modern language model. Most explanations present it as part of the full transformer architecture, alongside multi-head projections, residual connections, and positional encodings, which makes it hard to see what the core operation does on its own.
Here we build a small model that uses attention to learn a mapping between color words and nouns.
Given red, predict apple. Given blue, predict sky.
Attention computes similarity between a query vector and a set of key vectors, uses those similarities as weights, and returns a weighted sum of value vectors.
The Task
Our vocabulary has 14 tokens: 7 color words (indices 0–6) and 7 nouns (7–13). Each training
example is a (color_index, noun_index) pair sampled uniformly from the seven associations
below. The model takes a color index and must output a probability distribution over all 14
tokens, with the correct noun having the highest probability.
pairs = {
"red": "apple",
"blue": "sky",
"green": "leaf",
"yellow": "bird",
"orange": "car",
"purple": "rain",
"pink": "fur",
}
token_lookup = {
x: i for i, x in enumerate(list(pairs.keys()) + list(pairs.values()))
}
lookup_token = {i: x for x, i in token_lookup.items()}
vocab_size = len(token_lookup)
n_pairs = len(pairs)
encoded_pairs = [(token_lookup[k], token_lookup[v]) for k, v in pairs.items()]
We also need to define a function to sample arbitrary batches from the training pairs (we can generate arbitrary pairs for training given our low-cardinality).
def sequence(batch_size: int = 1024):
items = [random.choice(encoded_pairs) for i in range(batch_size)]
return torch.tensor(items, dtype=int)
sequence(batch_size=5)
The Math
Scaled dot-product attention is defined as:
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right) V\]Q, K, and V stand for Query, Key, and Value — borrowed from information retrieval. Q is the query (what we want to retrieve), K contains the keys that index each memory slot, and V contains the values to be returned.
Dot-product similarity. \(QK^\top \in \mathbb{R}^n\) gives a score for how well the query matches each of the \(n\) keys.
Scaling by \(\sqrt{d_k}\). Dot products in high-dimensional spaces tend to grow large, which pushes softmax into saturation — gradients vanish and learning stalls. Dividing by \(\sqrt{d_k}\) keeps scores in a usable range regardless of embedding dimension.
Softmax converts scores to attention weights \(\alpha \in \mathbb{R}^n\) that sum to 1:
\[\alpha_i = \frac{\exp\!\left(Q K_i^\top / \sqrt{d_k}\right)}{\displaystyle\sum_j \exp\!\left(Q K_j^\top / \sqrt{d_k}\right)}\]Retrieval is a weighted sum of value rows:
\[\text{context} = \sum_i \alpha_i V_i\]If \(\alpha\) were one-hot, this would be a hard lookup returning exactly \(V_j\). Softmax makes it a differentiable blend instead. Training pushes \(\alpha\) toward one-hot.
There’s a geometric interpretation as well - two vectors pointing in the same direction have a high dot product; two perpendicular vectors have a dot product of zero. The model exploits this directly: it learns to point each color’s query in the direction of its paired key, and away from all the others. After training, the ‘red’ query and its matched K row are nearly parallel; the ‘red’ query and any other K row are nearly orthogonal. Softmax turns that directional alignment into a near-winner-take-all selection.
The Architecture
In a standard transformer, K and V are projections of the input sequence. Here there is no
sequence. Instead, \(K \in \mathbb{R}^{7 \times d}\) and \(V \in \mathbb{R}^{7 \times d}\) are
free nn.Parameter tensors — a learned 7-slot associative memory. The forward pass is:
- The input color index goes through
nn.Embeddingto get a \(d\)-dimensional vector. - A linear projection \(W_q\) maps it to a query \(Q \in \mathbb{R}^d\).
- \(Q\) is compared against all 7 rows of \(K\) by scaled dot product, producing 7 scores.
- Softmax converts scores to attention weights over the 7 slots.
- The weighted sum of \(V\) rows gives a context vector, which a final linear layer decodes to logits.
The model has to learn two things at once: fill each \((K_i, V_i)\) slot with a useful representation of one pair, and learn \(W_q\) such that each color produces a query that aligns with the right key.
Nothing in the architecture enforces that K[i] and V[i] correspond to the same pair — that coupling is entirely enforced by the loss. If slot 3 consistently attracts ‘red’ queries but V[3] decodes to the wrong noun, cross-entropy stays high and gradients push V[3] toward ‘apple’ in the same backward pass that’s strengthening K[3]’s alignment with the ‘red’ query. K and V converge together to a consistent slot assignment. The failure mode is two colors converging on the same slot: K[i] gets pulled in two directions at once, neither pair fits cleanly, and loss stays elevated on both.
class AttentionModel(nn.Module):
def __init__(self, ndim: int = 16):
super().__init__()
self.ndim = ndim
self.embedding = nn.Embedding(vocab_size, ndim)
self.W_q = nn.Linear(ndim, ndim)
self.K = nn.Parameter(torch.randn(n_pairs, ndim))
self.V = nn.Parameter(torch.randn(n_pairs, ndim))
self.out = nn.Linear(ndim, vocab_size)
def forward(self, x):
# x: [batch] — color token indices
# embedded: [batch, ndim]
embedded = self.embedding(x)
# q: [batch, ndim] — learned query projection
q = self.W_q(embedded)
# scores: [batch, n_pairs] — similarity to each key, scaled
scores = (q @ self.K.T) / (self.ndim**0.5)
# weights: [batch, n_pairs] — soft selection (→ one-hot after training)
weights = scores.softmax(dim=-1)
# context: [batch, ndim] — retrieved value vector
context = weights @ self.V
# result: [batch, vocab_size] — logits over vocabulary
result = self.out(context)
return result
flowchart LR
X["x"] --> EMB["Embedding<br/>vocab_size × ndim"]
EMB --> WQ["W_q"]
WQ --> Q["Q [batch, ndim]"]
Q --> SCORES["Q @ K^T / sqrt ndim<br/>[batch, n_pairs]"]
K["K [n_pairs, ndim]<br/>nn.Parameter"] --> SCORES
SCORES --> W["softmax<br/>weights [batch, n_pairs]"]
W --> CTX["context = weights @ V<br/>[batch, ndim]"]
V["V [n_pairs, ndim]<br/>nn.Parameter"] --> CTX
CTX --> OUT["out Linear"]
OUT --> L["logits [batch, vocab_size]"]
L --> LOSS["CrossEntropyLoss"]
T["target noun idx"] --> LOSS
Training
epochs = 10_000
batch_size = 512
lr = 1e-3
ndim = 32
mo.md(rf"""
We minimize cross-entropy between the model's output logits and the target noun index using
Adam (lr={lr:.0e}), running {epochs:,} epochs at batch size {batch_size:,}. Each batch is sampled uniformly from
the 7 pairs.
The task has a perfect solution: a permutation matrix of attention weights, with each color
mapped to one dedicated key slot whose value decodes to the right noun. Loss should reach near
zero. The visualizations below show what the model learns.
""")
model = AttentionModel(ndim=ndim).to("cpu")
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_func = nn.CrossEntropyLoss()
for i in range(epochs):
optimizer.zero_grad()
next_batch = sequence(batch_size=batch_size)
outputs = model(next_batch[:, 0])
loss = loss_func(outputs, next_batch[:, 1])
loss.backward()
optimizer.step()
Results
test_results = []
attention_weights = []
with torch.no_grad():
for k in pairs.keys():
x = torch.tensor(token_lookup[k])
test_results.append(model(x).numpy())
q = model.W_q(model.embedding(x))
w = (q @ model.K.T / model.ndim**0.5).softmax(dim=-1)
attention_weights.append(w.numpy())
test_results = np.array(test_results)
attention_weights = np.array(attention_weights)
def build_inference_demo_plot():
plt.style.use("dark_background")
image_file = mo.notebook_dir() / "attention_inference_demo.png"
color_names = list(pairs.keys())
vocab_labels = [lookup_token[i] for i in range(len(lookup_token))]
predicted_idx = np.argmax(test_results, axis=1)
fig, ax = plt.subplots(figsize=(13, 4))
im = ax.imshow(test_results, aspect="auto", cmap="viridis")
ax.set_yticks(range(len(color_names)))
ax.set_yticklabels(
[
f"{c} → {lookup_token[predicted_idx[i]]}"
for i, c in enumerate(color_names)
]
)
ax.set_xticks(range(len(vocab_labels)))
ax.set_xticklabels(vocab_labels, rotation=45, ha="right")
ax.set_title(
"Output logits per color input (row label shows predicted token)"
)
fig.colorbar(im, ax=ax, label="logit")
plt.tight_layout()
plt.savefig(image_file)
return image_file
mo.image(build_inference_demo_plot())
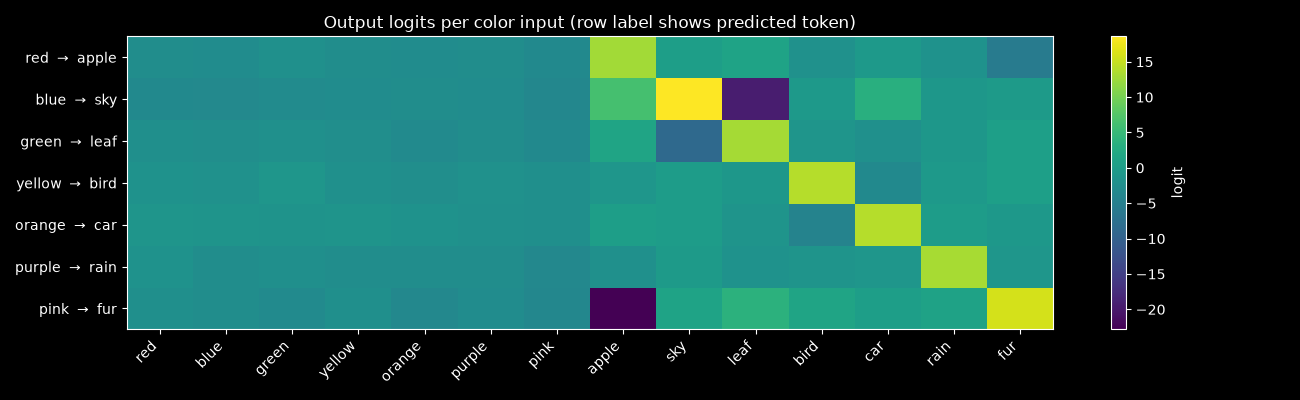
Each row shows output logits for one color input after training. The row label shows the predicted noun (argmax). Colors are in the left half of the x-axis (indices 0–6), nouns in the right half (7–13). A trained model should have high logit values concentrated on exactly one noun per row. Diffuse logits or wrong predictions mean the model hasn’t converged — try more epochs.
def build_k_v_plots():
plt.style.use("dark_background")
image_file = mo.notebook_dir() / "attention_k_v_plot.png"
color_names = list(pairs.keys())
noun_names = list(pairs.values())
# label each memory slot by whichever color attended to it most
dominant = [int(np.argmax(attention_weights[:, i])) for i in range(7)]
key_labels = [color_names[d] for d in dominant]
value_labels = [noun_names[d] for d in dominant]
fig, axarr = plt.subplots(1, 3, figsize=(16, 4))
im0 = axarr[0].imshow(
model.K.detach().numpy(), aspect="auto", cmap="coolwarm"
)
axarr[0].set_title("Learned Keys (K)")
axarr[0].set_yticks(range(7))
axarr[0].set_yticklabels(key_labels)
axarr[0].set_xlabel("dimension")
fig.colorbar(im0, ax=axarr[0])
im1 = axarr[1].imshow(
model.V.detach().numpy(), aspect="auto", cmap="coolwarm"
)
axarr[1].set_title("Learned Values (V)")
axarr[1].set_yticks(range(7))
axarr[1].set_yticklabels(value_labels)
axarr[1].set_xlabel("dimension")
fig.colorbar(im1, ax=axarr[1])
im2 = axarr[2].imshow(attention_weights, aspect="auto", cmap="viridis")
axarr[2].set_title("Attention weights\n(color query → key slot)")
axarr[2].set_yticks(range(len(color_names)))
axarr[2].set_yticklabels(color_names)
axarr[2].set_xticks(range(7))
axarr[2].set_xticklabels([f"K{i}" for i in range(7)], rotation=45)
fig.colorbar(im2, ax=axarr[2])
plt.tight_layout()
plt.savefig(image_file)
return image_file
mo.image(build_k_v_plots())
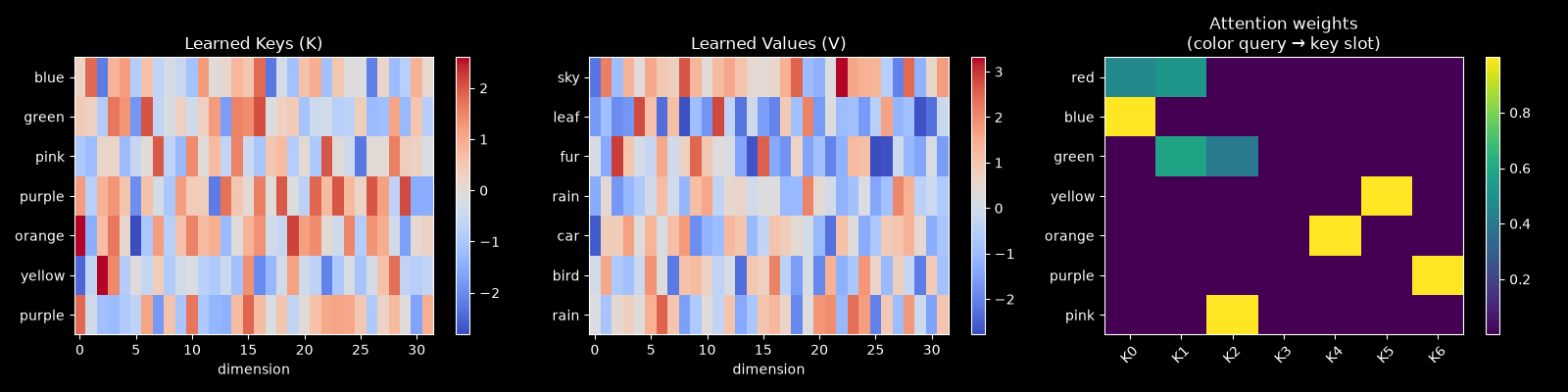
Attention weights (right). Each row is a color, each column a key slot. After training, this should look close to a permutation matrix — each color attending almost entirely to one slot, with no two colors sharing a key. This is attention functioning as a hard lookup table.
Keys and values (left, center). Each row is labeled by its dominant color or noun, based on which color attends to it most. The specific values matter less than the structure: keys need to be spread far enough apart in \(\mathbb{R}^d\) that queries can distinguish them, and values need to carry enough signal for the output layer to decode the right noun.
def build_geometry_gif():
image_file = mo.notebook_dir() / "attention_geometry.gif"
color_names = list(pairs.keys())
K = model.K.detach().numpy()
V = model.V.detach().numpy()
with torch.no_grad():
all_embs = model.embedding(
torch.tensor([token_lookup[c] for c in color_names])
).numpy()
all_queries = model.W_q(
model.embedding(
torch.tensor([token_lookup[c] for c in color_names])
)
).numpy()
# fixed PCA basis from all embeddings + all queries + K so compass stays stable
all_vecs = np.vstack([all_embs, all_queries, K])
_, _, Vt = np.linalg.svd(all_vecs - all_vecs.mean(0), full_matrices=False)
def unit_rows(M):
return M / np.linalg.norm(M, axis=1, keepdims=True).clip(1e-8)
k_proj = unit_rows((K - all_vecs.mean(0)) @ Vt[:2].T)
qkw = dict(
angles="xy",
scale_units="xy",
scale=1,
width=0.009,
headwidth=4,
headlength=5,
)
bg = "#0d1117"
frames = []
for color_idx, COLOR in enumerate(color_names):
j = int(np.argmax(attention_weights[color_idx]))
emb = all_embs[color_idx]
q = all_queries[color_idx]
scores = q @ K.T / (K.shape[1] ** 0.5)
exp_scores = np.exp(scores - scores.max())
weights = exp_scores / exp_scores.sum()
context = weights @ V
v_slot = V[j]
cos = float(
np.dot(context, v_slot)
/ np.clip(
np.linalg.norm(context) * np.linalg.norm(v_slot), 1e-8, None
)
)
mu = all_vecs.mean(0)
emb_u = unit_rows(((emb - mu) @ Vt[:2].T)[np.newaxis])[0]
q_u = unit_rows(((q - mu) @ Vt[:2].T)[np.newaxis])[0]
fig, axes = plt.subplots(1, 4, figsize=(18, 5))
fig.patch.set_facecolor(bg)
for ax in axes:
ax.set_facecolor(bg)
# Step 1: embed → W_q → Q
ax = axes[0]
ax.quiver(0, 0, emb_u[0], emb_u[1], color="royalblue", **qkw)
ax.quiver(0, 0, q_u[0], q_u[1], color="darkorange", **qkw)
ax.annotate(
f"embed({COLOR})",
emb_u,
xytext=(6, 4),
textcoords="offset points",
fontsize=9,
color="royalblue",
fontweight="bold",
)
ax.annotate(
"Q = W_q(·)",
q_u,
xytext=(6, -12),
textcoords="offset points",
fontsize=9,
color="darkorange",
fontweight="bold",
)
ax.set_xlim(-1.4, 1.4)
ax.set_ylim(-1.4, 1.4)
ax.set_aspect("equal")
ax.axhline(0, color="#30363d", lw=0.5)
ax.axvline(0, color="#30363d", lw=0.5)
ax.set_title(
f"Step 1\nembed({COLOR}) → W_q → Q", fontsize=10, color="#f0f6fc"
)
ax.set_xlabel("PC 1", color="#8b949e")
ax.set_ylabel("PC 2", color="#8b949e")
ax.tick_params(colors="#8b949e")
for sp in ax.spines.values():
sp.set_color("#30363d")
# Step 2: Q vs all key vectors
ax = axes[1]
for i in range(7):
is_match = i == j
c = "steelblue" if is_match else "#484f58"
alpha = 1.0 if is_match else 0.5
scale = 0.88 if is_match else 0.75
ax.quiver(
0,
0,
k_proj[i, 0] * scale,
k_proj[i, 1] * scale,
color=c,
alpha=alpha,
**qkw,
)
label = "K[j]" if is_match else f"K[{i}]"
ax.annotate(
label,
k_proj[i] * scale,
xytext=(4, -10),
textcoords="offset points",
fontsize=8,
color=c if is_match else "#484f58",
alpha=alpha,
)
ax.quiver(0, 0, q_u[0], q_u[1], color="darkorange", zorder=5, **qkw)
ax.annotate(
f"Q:{COLOR}",
q_u,
xytext=(5, 4),
textcoords="offset points",
fontsize=9,
color="darkorange",
fontweight="bold",
)
ax.set_xlim(-1.4, 1.4)
ax.set_ylim(-1.4, 1.4)
ax.set_aspect("equal")
ax.axhline(0, color="#30363d", lw=0.5)
ax.axvline(0, color="#30363d", lw=0.5)
ax.set_title(
"Step 2\nQ aligns with matched key K[j]",
fontsize=10,
color="#f0f6fc",
)
ax.set_xlabel("PC 1", color="#8b949e")
ax.set_ylabel("PC 2", color="#8b949e")
ax.tick_params(colors="#8b949e")
for sp in ax.spines.values():
sp.set_color("#30363d")
# Step 3: softmax weights
ax = axes[2]
slot_labels = ["K[j]" if i == j else f"K[{i}]" for i in range(7)]
bar_colors = ["steelblue" if i == j else "#2d333b" for i in range(7)]
ax.bar(
range(7),
weights,
color=bar_colors,
edgecolor="#484f58",
linewidth=0.5,
)
ax.set_xticks(range(7))
ax.set_xticklabels(slot_labels, fontsize=9, color="#8b949e")
ax.set_ylabel("weight", color="#8b949e")
ax.set_ylim(0, 1.05)
ax.axhline(
1 / 7, color="#484f58", linestyle="--", alpha=0.7, linewidth=1
)
ax.annotate(
"1/7 (uniform)",
xy=(6.4, 1 / 7 + 0.025),
fontsize=8,
color="#484f58",
ha="right",
)
ax.set_title(
"Step 3\nsoftmax(scores) → weights", fontsize=10, color="#f0f6fc"
)
ax.tick_params(colors="#8b949e")
ax.grid(True, axis="y", color="#21262d", lw=0.5)
for sp in ax.spines.values():
sp.set_color("#30363d")
# Step 4: context ≈ V[j]
ax = axes[3]
v_max = max(
float(np.abs(v_slot).max()), float(np.abs(context).max()), 1e-8
)
x_dim = np.arange(len(v_slot))
ax.bar(
x_dim - 0.2,
v_slot / v_max,
width=0.4,
color="steelblue",
alpha=0.85,
label="V[j]",
)
ax.bar(
x_dim + 0.2,
context / v_max,
width=0.4,
color="darkorange",
alpha=0.85,
label="context",
)
ax.set_xlabel("dimension", color="#8b949e")
ax.set_ylabel("value (normalized)", color="#8b949e")
ax.set_title(
f"Step 4\ncontext ≈ V[j] (cosine = {cos:.2f})",
fontsize=10,
color="#f0f6fc",
)
ax.legend(
fontsize=8,
facecolor="#161b22",
edgecolor="#30363d",
labelcolor="#f0f6fc",
)
ax.tick_params(colors="#8b949e")
ax.grid(True, axis="y", color="#21262d", lw=0.5)
for sp in ax.spines.values():
sp.set_color("#30363d")
fig.suptitle(
f'Attention walkthrough: "{COLOR}" → "{pairs[COLOR]}"',
fontweight="bold",
fontsize=13,
color="#f0f6fc",
)
fig.subplots_adjust(
left=0.05, right=0.99, top=0.85, bottom=0.18, wspace=0.38
)
buf = io.BytesIO()
plt.savefig(buf, format="png", bbox_inches="tight", dpi=72)
buf.seek(0)
frames.append(Image.open(buf).convert("RGB"))
buf.close()
plt.close(fig)
all_frames = frames + frames[-2:0:-1]
all_frames[0].save(
image_file,
save_all=True,
append_images=all_frames[1:],
loop=0,
duration=1000,
format="GIF",
)
return image_file
mo.image(build_geometry_gif())
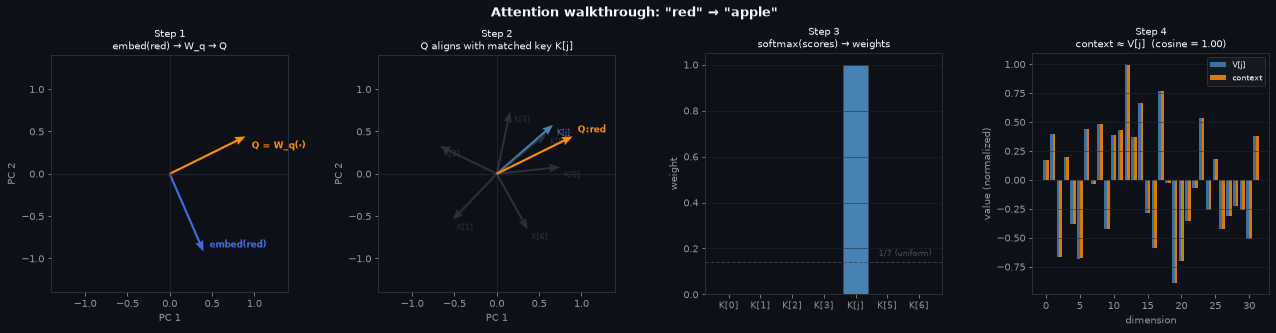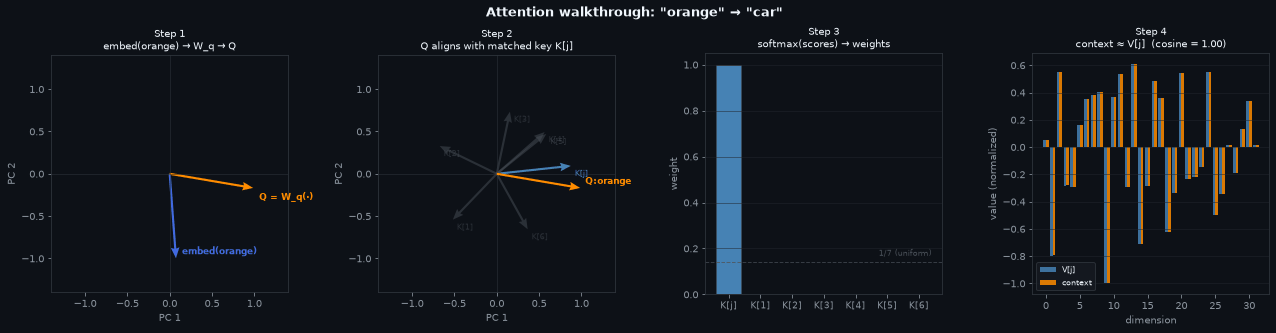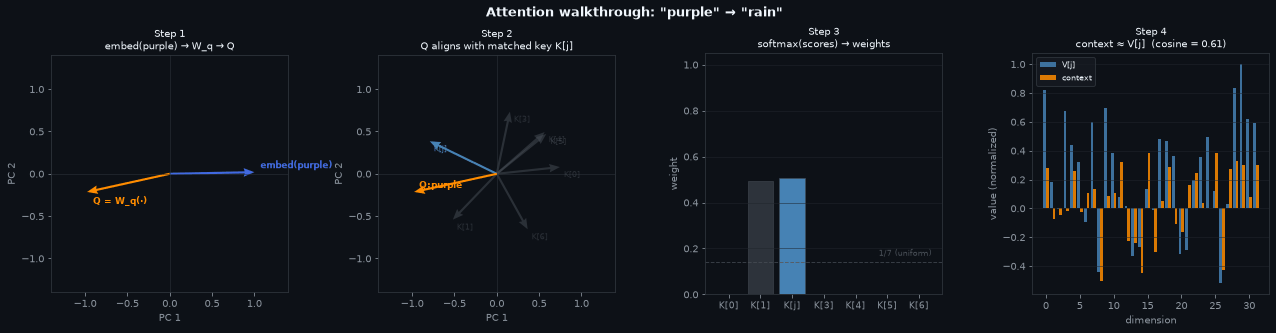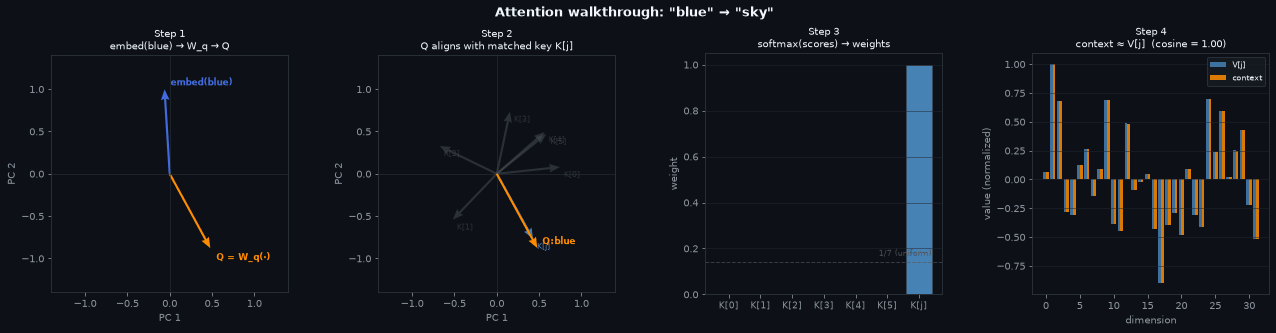
Each panel traces one forward pass through the attention mechanism, cycling through each input color in turn. All vector directions are shown in a shared 2D PCA projection with a fixed basis so the key compass stays stable across frames.
Step 1 — The embedding lookup gives a \(d\)-dimensional vector for “blue” (blue arrow). \(W_q\) projects it to the query \(Q\) (orange arrow). The direction changes: \(W_q\) is a learned rotation and scaling whose job is to point \(Q\) toward the right key.
Step 2 — \(Q\) (orange) is plotted alongside all 7 key vectors (gray). The matched key \(K[j]\) is the slot that “blue” attends to most. After training, \(Q\) and \(K[j]\) are nearly collinear — high dot product, low dot product with everything else.
Step 3 — Scaling by \(1/\sqrt{d}\) and applying softmax turns the raw scores into weights. A well-trained model produces a near-one-hot distribution: almost all weight on the single matched slot, near-zero everywhere else. The dashed line marks uniform (1/7) for reference.
Step 4 — Throughout, \(j\) denotes the matched slot: \(j = \arg\max_i \, \alpha_i\).
\(V \in \mathbb{R}^{7 \times d}\) is a free nn.Parameter matrix — a learned
memory bank with one row per slot. Nothing in the architecture prescribes what those rows
contain; they are initialized randomly and shaped entirely by gradient descent.
The context vector is:
\[\text{context} = \sum_{i=0}^{6} \alpha_i \, V_i\]When \(\alpha\) is near-one-hot (Step 3), almost all weight is on slot \(j\), so nearly every other \(V_i\) is multiplied by \(\approx 0\). What survives is \(\approx V[j]\).
Why does \(V[j]\) encode “sky”? Cross-entropy loss. Every time “blue” is the input, the model attends to slot \(j\) and returns \(V[j]\) as context. The output linear layer then has to decode that context to a high logit for “sky”. If \(V[j]\) doesn’t support that decoding, the loss stays high and gradients push \(V[j]\) in a direction that does. \(K[j]\) and \(V[j]\) are separate parameters but they converge together: \(K[j]\) becomes the address that “blue” queries, \(V[j]\) becomes the content that decodes to the paired noun.
The two bars in the plot show that the retrieved context (orange) and \(V[j]\) (blue) are nearly identical — the cosine similarity in the title confirms it. The small residual comes from the non-zero weight on the other slots.
Putting It Together
The plots above each show one part of the attention mechanism in isolation. This final plot traces a complete lookup end to end for each input color — cycling through all seven in turn — showing which key the query selected, what was retrieved from that key, and where the retrieved value landed in output space.
The three panels share axes so you can trace a specific slot across all of them. The column axis of the left panel is the same as the bar axis of the centre panel — both index the seven key slots. Find the slot that the current color attends to in the left panel, look at the same column in the centre panel to see its weight, then follow that weight through to the output logits on the right.
def build_trace_gif():
img_file = mo.notebook_dir() / "attention_trace.gif"
color_names = list(pairs.keys())
with torch.no_grad():
all_tokens = torch.tensor([token_lookup[c] for c in color_names])
all_queries = model.W_q(model.embedding(all_tokens))
weights_all = (
(all_queries @ model.K.T / model.ndim**0.5).softmax(dim=-1).numpy()
)
V_np = model.V.detach().numpy()
all_logits = [
model(torch.tensor(token_lookup[c])).numpy() for c in color_names
]
vocab_labels = [lookup_token[i] for i in range(vocab_size)]
bg = "#0d1117"
frames = []
for input_idx, INPUT_COLOR in enumerate(color_names):
w_color = weights_all[input_idx]
j = int(np.argmax(w_color))
v_slot = V_np[j]
context = w_color @ V_np
cos = float(
np.dot(context, v_slot)
/ np.clip(
np.linalg.norm(context) * np.linalg.norm(v_slot), 1e-8, None
)
)
logits = all_logits[input_idx]
correct_noun_idx = token_lookup[pairs[INPUT_COLOR]]
fig = plt.figure(figsize=(18, 5))
fig.patch.set_facecolor(bg)
gs = fig.add_gridspec(1, 3, width_ratios=[2, 1, 2], wspace=0.38)
ax0 = fig.add_subplot(gs[0])
ax0.set_facecolor(bg)
im = ax0.imshow(
weights_all, aspect="auto", cmap="plasma", vmin=0, vmax=1
)
ax0.set_xticks(range(7))
ax0.set_xticklabels(
[f"K[{i}]" for i in range(7)], fontsize=8, color="#8b949e"
)
ax0.set_yticks(range(7))
ax0.set_yticklabels(color_names, fontsize=9, color="#8b949e")
for y in [input_idx - 0.5, input_idx + 0.5]:
ax0.axhline(y, color="#f0f6fc", linewidth=1.2, alpha=0.6)
for x in [j - 0.5, j + 0.5]:
ax0.axvline(x, color="#58a6ff", linewidth=1.2, alpha=0.6)
ax0.set_title(
f'Attention weights — query: "{INPUT_COLOR}" (white), matched slot: K[{j}] (blue)',
color="#f0f6fc",
fontsize=10,
)
ax0.tick_params(colors="#8b949e")
for sp in ax0.spines.values():
sp.set_color("#30363d")
cb = fig.colorbar(im, ax=ax0, fraction=0.05, pad=0.02)
cb.ax.tick_params(colors="#8b949e")
cb.outline.set_edgecolor("#30363d")
gs2 = gs[1].subgridspec(2, 1, hspace=0.65)
ax1a = fig.add_subplot(gs2[0])
ax1a.set_facecolor(bg)
ax1a.bar(
range(7),
w_color,
color=["#58a6ff" if i == j else "#2d333b" for i in range(7)],
linewidth=0,
)
ax1a.set_xticks(range(7))
ax1a.set_xticklabels(
[f"K[{i}]" for i in range(7)],
fontsize=7,
color="#8b949e",
rotation=45,
ha="right",
)
ax1a.axhline(1 / 7, color="#484f58", linestyle="--", linewidth=0.8)
ax1a.set_ylim(0, 1.05)
ax1a.set_ylabel("α", color="#8b949e", fontsize=8)
ax1a.set_title(
f'"{INPUT_COLOR}" weights — slot {j} wins',
color="#f0f6fc",
fontsize=9,
)
ax1a.tick_params(colors="#8b949e", labelsize=7)
for sp in ax1a.spines.values():
sp.set_color("#30363d")
ax1b = fig.add_subplot(gs2[1])
ax1b.set_facecolor(bg)
scale = max(
float(np.abs(v_slot).max()), float(np.abs(context).max()), 1e-8
)
dims = np.arange(model.ndim)
ax1b.bar(
dims - 0.2,
v_slot / scale,
width=0.4,
color="#58a6ff",
alpha=0.85,
label=f"V[{j}]",
)
ax1b.bar(
dims + 0.2,
context / scale,
width=0.4,
color="#f0883e",
alpha=0.85,
label="context",
)
ax1b.set_title(
f"context ≈ V[{j}] (cos = {cos:.2f})", color="#f0f6fc", fontsize=9
)
ax1b.tick_params(colors="#8b949e", labelsize=6)
ax1b.set_xlabel("dimension", color="#8b949e", fontsize=7)
ax1b.legend(
fontsize=7,
facecolor="#161b22",
edgecolor="#30363d",
labelcolor="#f0f6fc",
loc="upper right",
)
for sp in ax1b.spines.values():
sp.set_color("#30363d")
ax2 = fig.add_subplot(gs[2])
ax2.set_facecolor(bg)
bar_out = [
"#3fb950"
if i == correct_noun_idx
else "#2d333b"
if i < 7
else "#58a6ff"
for i in range(vocab_size)
]
ax2.bar(range(vocab_size), logits, color=bar_out, linewidth=0)
ax2.set_xticks(range(vocab_size))
ax2.set_xticklabels(
vocab_labels, rotation=45, ha="right", fontsize=8, color="#8b949e"
)
ax2.axhline(0, color="#30363d", linewidth=0.8)
ax2.set_title(
f'Output logits: "{INPUT_COLOR}" → "{lookup_token[int(np.argmax(logits))]}"',
color="#f0f6fc",
fontsize=10,
)
ax2.set_ylabel("logit", color="#8b949e")
ax2.tick_params(colors="#8b949e")
ax2.grid(True, axis="y", color="#21262d", linewidth=0.5)
for sp in ax2.spines.values():
sp.set_color("#30363d")
ax2.legend(
handles=[
Patch(facecolor="#3fb950", label="correct noun"),
Patch(facecolor="#58a6ff", label="other nouns"),
Patch(facecolor="#2d333b", label="color tokens"),
],
fontsize=7,
facecolor="#161b22",
edgecolor="#30363d",
labelcolor="#f0f6fc",
)
fig.suptitle(
f'Complete lookup trace: "{INPUT_COLOR}" → "{pairs[INPUT_COLOR]}"',
color="#f0f6fc",
fontweight="bold",
fontsize=13,
)
buf = io.BytesIO()
plt.savefig(buf, format="png", bbox_inches="tight", dpi=72)
buf.seek(0)
frames.append(Image.open(buf).convert("RGB"))
buf.close()
plt.close(fig)
all_frames = frames + frames[-2:0:-1]
all_frames[0].save(
img_file,
save_all=True,
append_images=all_frames[1:],
loop=0,
duration=1000,
format="GIF",
)
return img_file
mo.image(build_trace_gif(), width=950)
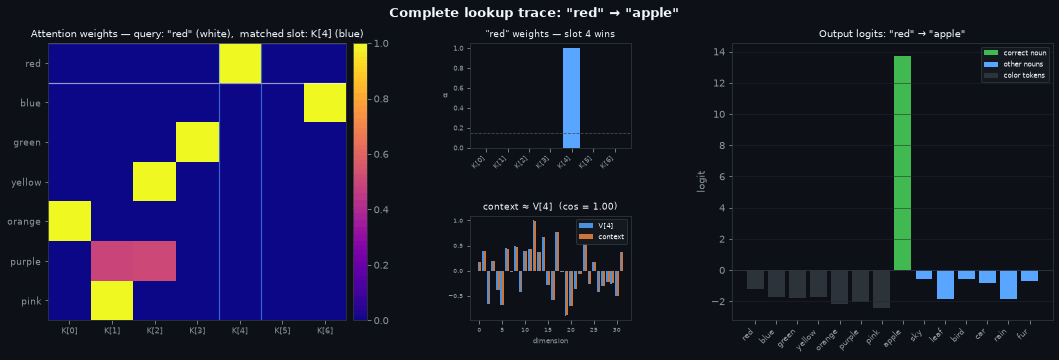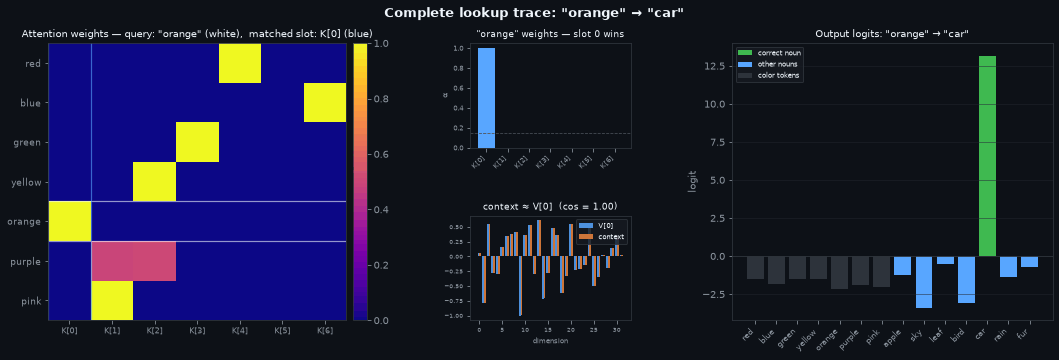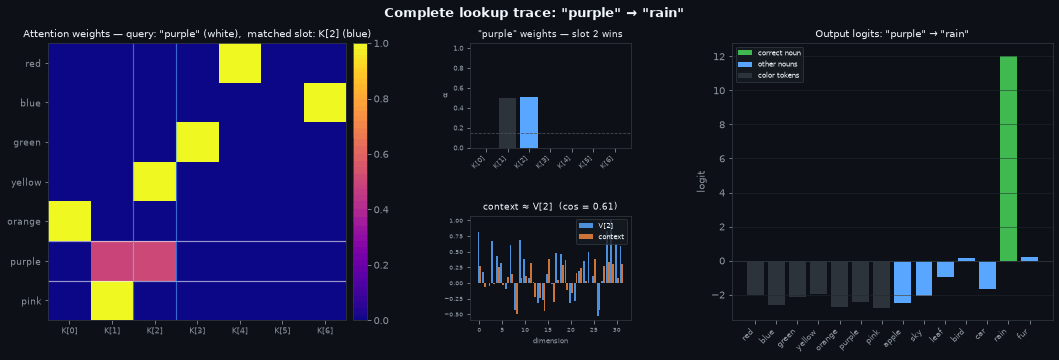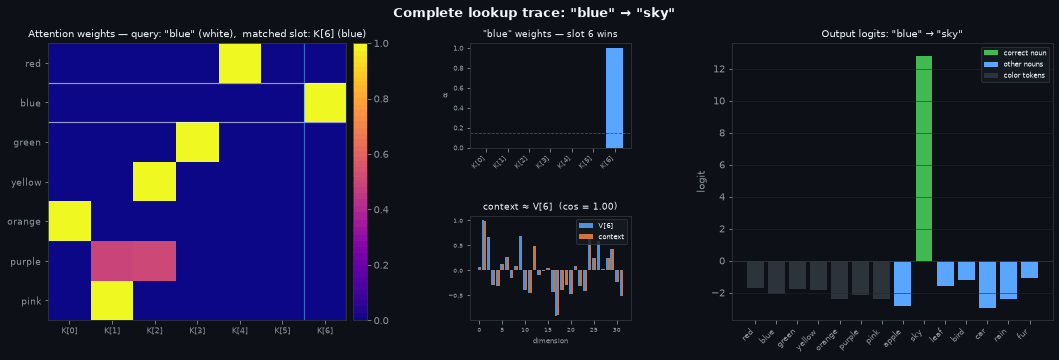
Left — the lookup table. Every row is a trained color query; every column is a key slot. After training this matrix is close to a permutation: each color claims one slot with near-zero weight everywhere else. The white lines trace the current color’s row; the blue lines mark the slot it matched. The bright cell at their intersection is the query-key pair that fired.
Centre — the retrieval. Top: the current color’s attention weights. Almost all weight sits on slot \(j\) (highlighted bar); the dashed line marks 1/7, the uniform baseline. The column index here is the same as in the left panel — you can trace a specific slot from the heatmap directly to its weight bar. Bottom: the retrieved context (orange) overlaid on \(V[j]\) (blue), the value stored in that slot. They are nearly identical because the near-one-hot weight collapsed the weighted sum to a single term.
Right — the answer. Output logits over the full vocabulary. Color tokens (dark) get low logits — the model has learned the answer is always a noun. Among the seven nouns (blue), the correct one (green) is highest. The logit gap reflects retrieval quality: a sharp attention weight produces a clean context vector, which the output layer decodes to a confident prediction.
Takeaway
The main difference between attention and a regular linear layer is that attention is input-dependent. A linear layer applies the same weights regardless of input. Attention uses the input to generate a query first, then uses that query to decide what to retrieve.
In a full transformer, this runs across many heads and positions, with K and V derived from other tokens rather than stored as free parameters. But the computation — \(\text{softmax}(QK^\top / \sqrt{d})V\) — is the same.