Interpolating Data
Adapted from Numerical Computation Homeworks
This is adapted from separate Jupyter Notebook formatted homeworks. I’ve updated a few statements for clarity but otherwise the content has remained the same as it was written originally.
Interpolating 1D
Imports
import numpy as np
import matplotlib.pyplot as plt
import numpy.linalg as npl
import scipy.interpolate as scit
%pylab inline
Basic Linear Interpolation
- Implement a program that takes two input points, \(x^*\), and returns the interpolated line calculated at \(x^*\).
def linear_interpolation(point1, point2):
"""
Interpolates a line between two given points.
:param point[12]: tuple(float, float)
Coordinates for points
:returns: function
Equation for interpolated line
"""
return lambda x: (point1[1] +
((point1[1] - point2[1]) /
(point1[0] - point2[0])) *
(x - point1[0]))
def linearpoint(point1, point2, x):
return linear_interpolation(point1, point2)(x)
Linear Interpolation Applied
a) The following data show the mean annual \(CO_2\) levels measured at the top of Mauna Loa at 10 year intervals. User your program to estimate the mean annual \(CO_2\) level at the top of Mauna Loa in 2005.
data = np.array([[1960, 316.91],
[1970, 325.68],
[1980, 338.68],
[1990, 354.35],
[2000, 369.52],
[2010, 389.85]])
domain = data[:, 0]
line = linear_interpolation(data[-2], data[-1])
point = linearpoint(data[-2], data[-1], 2005)
plt.figure()
plt.plot(data[:, 0], data[:, 1])
plt.plot(domain, line(domain))
plt.scatter(2005, point)
plt.ylabel(r' $$ CO_2 $$ Level')
plt.xlabel('Year')
plt.show()
print(point)
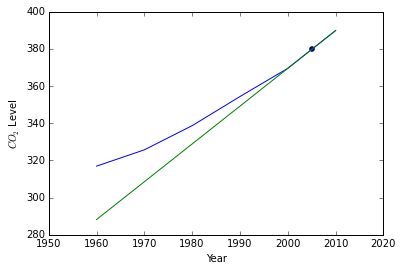
379.685
b) The true value in 2005 was 379.80. What was the absoluate error in your interpolated value? What about the relative error?
| Absolute error is defined as $$ | v - v_{approx} | \(while relative error is defined as\) \lvert 1 - \frac{v_{approx} }{v} \rvert $$. |
v = 379.8
print(f'Absolute error is {np.abs(v - point)}'
print(f'Relative error is {np.abs(1 - (point / v)`)}')
Absolute error is 0.1150000000000091
Relative error is 0.0003027909426014386
Basic Linear Extrapolation
- The same idea can be applied in order to extrapolate. Using the same data and code in problem 1 estimate the mean level in 2014.
Since we are given the actual answer we can extrapolate and determine the best fitting line for the future by comparing every line versus every line.
data = np.array([[1960, 316.91],
[1970, 325.68],
[1980, 338.68],
[1990, 354.35],
[2000, 369.52],
[2010, 389.85]])
domain = np.append(data[:, 0], 2014)
error = 10
best = None
plt.figure()
for i in range(len(data)):
for j in range(len(data)):
if i != j:
line = linear_interpolation(data[i], data[j])
if np.abs(398.55 - line(2014)) < error:
best = line(2014)
plt.plot(domain, line(domain), '--')
plt.plot(data[:, 0], data[:, 1], 'k-', linewidth=3)
plt.scatter(2014, 398.55)
plt.ylabel(r' $$ CO_2 $$ Level')
plt.xlabel('Year')
plt.show()
print(best)
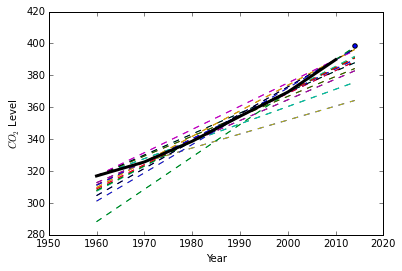
397.982
Plotting
- Plot every line so far.
data = np.array([[1960, 316.91],
[1970, 325.68],
[1980, 338.68],
[1990, 354.35],
[2000, 369.52],
[2010, 389.85]])
domain = np.append(data[:, 0], 2014)
line = linear_interpolation(data[-2], data[-1])
error = 10
best = None
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
ax.plot(domain, line(domain), label='Interpolated Line')
ax.plot(data[:, 0], data[:, 1], label='Data')
ax.scatter(2014, 398.55, label='2014 Point')
ax.scatter(2005, linearpoint(data[-2], data[-1], 2005), label='2014 Point')
plt.ylabel(r' $$ CO_2 $$ Level')
plt.xlabel('Year')
plt.legend(loc=4)
plt.show()
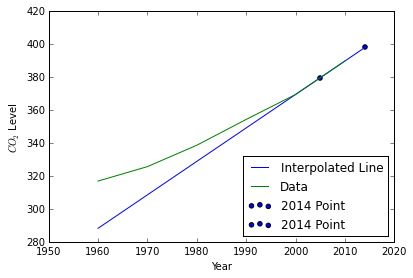
Lagrangian Interopolation
- Use the Lagrangian interpolating polynomial approach to fit a parabola to the last three points in the data. Use that polynomial to estimate the \(CO_2\) level in 2005. Compare that to the value obtained in problem 1, as well as the true value. Which is better? Does that make sense?
def lagrangian_polynomial(points, xarr):
"""
Lagrangian Polynomial at a set of points
"""
if type(xarr) in [int, float]:
return lagrangian_point(points, xarr)
else:
return np.array([lagrangian_point(points, x) for x in xarr])
def lagrangian_point(points, x):
"""
Finds the Langrangian interpolating polynomial
in two dimensions at point x
A set of k points.
See http://en.wikipedia.org/wiki/Lagrange_polynomial
"""
Lx = []
for j in range(len(points)):
lx = []
for m in range(len(points)):
if m != j:
lx.append(((x - points[m, 0]) /
(points[j, 0] - points[m, 0])))
Lx.append(points[j, 1] * np.prod(lx))
Lx = np.sum(Lx)
return Lx
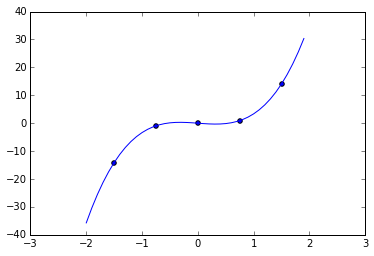
Using test data found on the wiki link above we establish that our algorithm is correct.
data = np.array([[-1.5, -14.1014],
[-0.75, -0.931596],
[0, 0],
[0.75, 0.931596],
[1.5, 14.1014]])
plt.figure()
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.arange(-2, 2, 0.1),
lagrangian_polynomial(data, np.arange(-2, 2, 0.1)))
plt.show()
Now we use the \(CO_2\) data.
data = np.array([[1960, 316.91],
[1970, 325.68],
[1980, 338.68],
[1990, 354.35],
[2000, 369.52],
[2010, 389.85]])
plt.figure()
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.arange(1960, 2015, 1),
lagrangian_polynomial(data[-3:], np.arange(1960, 2015, 1)))
plt.ylabel(r' $$ CO_2 $$ Level')
plt.xlabel('Year')
plt.show()
print(lagrangian_polynomial(data[-3:], 2005))
379.04
We’ll note that this new value of \(\approx 379.04\) is actually worse than our estimated value using linear interpolation of \(\approx 379.6\) given the true value in 2005 to be \(379.8\). This shouldn’t be the case, and in fact almost presents a case against using lagrangian interpolation, however the advantage lagrangian interpolation gives us is that it should be more accurate in general than generic linear interpolation.
Newton’s Divided Differences
- Use Newton’s divided differences to fit a parabola to the last three points in the data table above. Do you get the same polynomial as in the previous problem? Should you?
def divided_differences(data):
""" http://mathworld.wolfram.com/DividedDifference.html """
if len(data) == 1:
return data[0, 1]
else:
return ((divided_differences(data[:-1]) -
divided_differences(data[1:])) /
(data[0, 0] - data[-1, 0]))
def newtons_differences(points, xarr):
"""
Lagrangian Polynomial at a set of points
"""
if type(xarr) in [int, float]:
return newtons_differences_point(points, xarr)
else:
return np.array([newtons_differences_point(points, x)
for x in xarr])
def newtons_differences_point(data, x):
"""
Newton's divided differences for polynomials
http://en.wikipedia.org/wiki/Newton_polynomial
http://mathworld.wolfram.com/NewtonsDividedDifferenceInterpolationFormula.html
"""
pin = lambda y, n: np.prod([(y - data[k, 0])
for k in range(n)])
Nx = data[0, 1]
for i in range(1, len(data)):
Nx += pin(x, i) * divided_differences(data[:i + 1])
return Nx
data = np.array([[1960, 316.91],
[1970, 325.68],
[1980, 338.68],
[1990, 354.35],
[2000, 369.52],
[2010, 389.85]])
plt.figure()
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.arange(1960, 2015, 1),
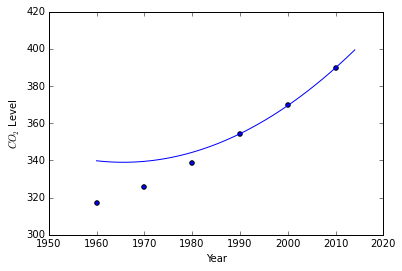
newtons_differences(data[-3:], np.arange(1960, 2015, 1)))
plt.ylabel(r' $$ CO_2 $$ Level')
plt.xlabel('Year')
plt.show()
We appear to get the same polynomial, which makes sense. These two polynomials should be of the same form.
Cubic Natural Spline
- Fit a cubic natural spline to the last three points in the data table above. Using some sort of computer plotting tool, please plot this spline, along with the data from the table above, the true value at 2005, and your parabola from problem 5. Comment on similarities and differences between the spline and the parabola: their shapes, the accuracy of the interpolated value that each one produces, etc.
def cubic_natural_spline(data):
"""
Fits a cubic spline to the points
"""
a = np.zeros((len(data), len(data)), dtype=int)
b = np.zeros((len(data), 1))
a[0, 0] = 1
a[-1, -1] = 1
xdelta = lambda c: data[c + 1, 0] - data[c, 0]
ydelta = lambda c: data[c + 1, 1] - data[c, 1]
# System of equations
for i in range(1, len(data) - 1):
for j in range(len(data)):
if i - 1 == j:
a[i, j] = xdelta(i - 1)
if i == j:
a[i, j] = (2 * xdelta(i - 1) +
2 * xdelta(i))
if i + 1 == j:
a[i, j] = xdelta(i)
for i in range(1, len(data) - 1):
b[i, 0] = 3 * ((ydelta(i) / xdelta(i)) -
(ydelta(i - 1) / xdelta(i - 1)))
# We've already written a matrix solver
sols = npl.solve(a, b)
# Extract splines
splines = []
for i in range(len(data) - 1):
d = (sols[i + 1] - sols[i]) / (3 * xdelta(i))
b = (ydelta(i) / xdelta(i)) - ((xdelta(i) / 3) *
(2 * sols[i] + sols[i + 1]))
splines.append(lambda x: data[i, 1] +
b * (x - data[i, 0]) +
sols[i] * (x - data[i, 0])**2 +
d * (x - data[i, 0])**3)
return splines
data = np.array([[1960, 316.91],
[1970, 325.68],
[1980, 338.68],
[1990, 354.35],
[2000, 369.52],
[2010, 389.85]])
plt.figure()
# All collected points
plt.scatter(data[:, 0], data[:, 1])
plt.scatter(2005, 379.80)
# Problem 5 curve
plt.plot(np.arange(1960, 2015, 1),
newtons_differences(data[-3:], np.arange(1960, 2015, 1)))
# Cubic Spline
splines = cubic_natural_spline(data[-3:])
for i in range(len(splines)):
plt.plot(np.arange(data[i - 3, 0], data[i - 2, 0], 0.1),
splines[i](np.arange(data[i - 3, 0], data[i - 2, 0], 0.1)),
'r-')
plt.ylabel(r' $$ CO_2 $$ Level')
plt.xlabel('Year')
plt.show()
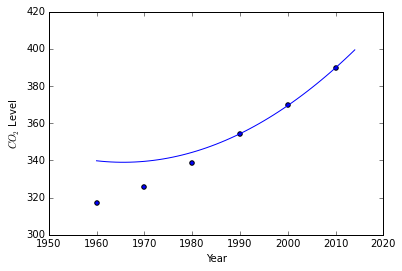
print("True Value:\t{}\nNewton's:\t{}\nCubic Spline:\t{}".format(
379.80, newtons_differences(data[-3:], 2005),
splines[1](2005)[0]))
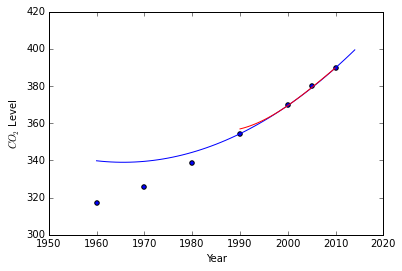
True Value: 379.8
Newton's: 379.03999999999996
Cubic Spline: 379.20125
Examining our natural cubic spline compared to our fitted interpolating polynomial we see that the two lines are very close to one another, however the cubic spline is closest to the true value.
If more points were used (i.e. the entire dataset, or even a much larger dataset) we would be able to estimate these points with much higher accuracy, because as it is 3 points is just too little.
The shapes of the generated curves are very similar. Both curve toward the true points, ending on the polynomial as \(x \to 2010\), however this can again be attributed to the fact that our dataset is so small. A larger dataset would produce a polynomial that would actually stick to the data.
The implementations of the Lagrangian Polynomial and the Newton polynomial are not very efficient. They will not scale, and should only be used for a limited set of points.
Splines
import numpy as np
import matplotlib.pyplot as plt
%pylab inline
External Tools
- Play with
xfig. Play with the four-spline and curve-drawing tools. Use your knowledge about different kinds of splines, do some experiments, and form some conjectures about which onesxfiguses for the tool who’s icon looks like a smooth figure eight and the one that looks like a figure eight with superimposed dots. With each answer, turn in a few sentences that describe your rationale for making that diagnosis.
The curve-drawing tool draw’s bezier curves. We can see this by examining a couple examples from class using different sets of lines.
from IPython.display import Image
Image(filename='bezier.png')
from IPython.display import Image
Image(filename='bezierclosed.png')
Not only does this seem to look like a bezier curve, but we can also imagine the “magnetic force” pulling the lines in the directions. In this case it’s really the point placement that informs us that these are bezier curves.
Examining the spline tools we can take the exact same set of points and look at the differences
from IPython.display import Image
Image(filename='spline.png')
from IPython.display import Image
Image(filename='splineclosed.png')
Using what we know about spline interpolation we can safely assume that this tool using splines since the line passes thgouh each point.
The only difference in the “figure-eight” and the “s” shaped tools is that the closed loop tool (“figure-eight”) simply connects the first and last point when it has drawn all previous points.
Bezier Implementation
- Implement a Cubic Bezier Polynomial generator. This should take a specific multiple of input points and then return the curves.
First we create our function.
def bezier(points):
"""
Draw's bezier polynomials.
"""
if len(points) % 3 != 1:
print('Please submit 1+3n points.')
return
# Have to curry because of Python Scope problems
def createcurve(p0, p1, p2, p3):
return lambda tarr: np.array([((1 - t)**3 * p0 +
3 * (1 - t)**2 * t * p1 +
3 * (1 - t) * t**2 * p2 +
t**3 * p3) for t in tarr])
curves = []
for i in range(int(len(points) / 4) + 1):
curves.append(createcurve(points[3 * i],
points[3 * i + 1],
points[3 * i + 2],
points[3 * i + 3]))
if len(points) == 4:
break
return curves
Now we can run a bunch of points through our curve-generator and see what we get.
plt.figure(figsize=(10, 10))
points = np.array([[0, -2],
[-2, -2],
[-2, 0],
[0, 0],
[0, 2],
[2, 2],
[2, 0],
[2, 2],
[4, -4],
[4, 0]])
curves = bezier(points)
plt.scatter(points[:, 0], points[:, 1])
for i in range(int(len(points) / 4) + 1):
plt.plot(curves[i](np.arange(0, 1, 0.01))[:, 0],
curves[i](np.arange(0, 1, 0.01))[:, 1])
plt.plot(points[3 * i:3 * i + 2, 0],
points[3 * i:3 * i + 2, 1], 'k--')
plt.plot(points[3 * i + 2:3 * i + 4, 0],
points[3 * i + 2:3 * i + 4, 1], 'k--')
plt.show()
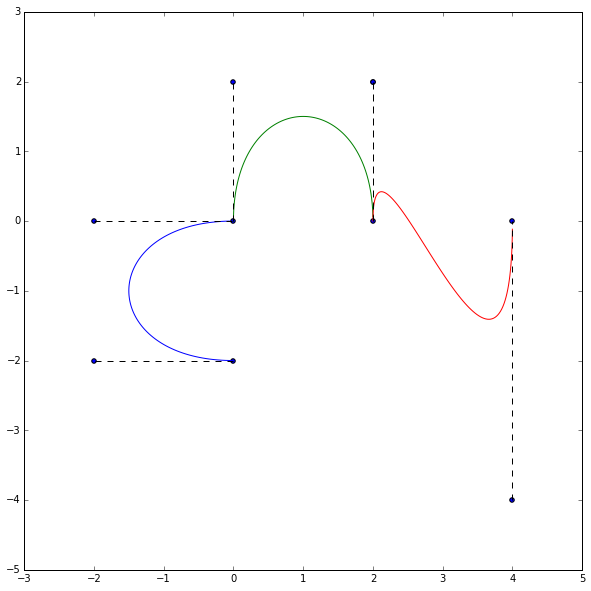
Now we can try to replicate some of the examples.
plt.figure(figsize=(10, 10))
points = np.array([[0, 0],
[1.2, 1],
[-0.2, 1],
[1, 0],
[1.4, 1],
[3, 1],
[2, 0]])
curves = bezier(points)
plt.scatter(points[:, 0], points[:, 1])
for i in range(int(len(points) / 4) + 1):
plt.plot(curves[i](np.arange(0, 1, 0.01))[:, 0],
curves[i](np.arange(0, 1, 0.01))[:, 1])
plt.plot(points[3 * i:3 * i + 2, 0],
points[3 * i:3 * i + 2, 1], 'k--')
plt.plot(points[3 * i + 2:3 * i + 4, 0],
points[3 * i + 2:3 * i + 4, 1], 'k--')
plt.show()
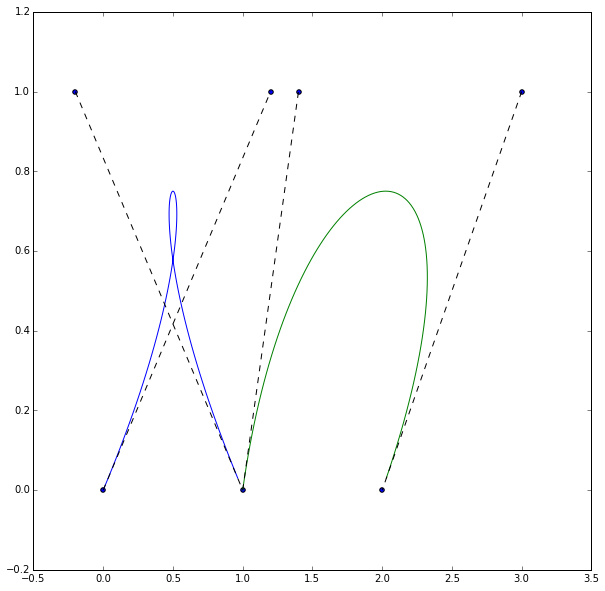
Neat.